














챗GPT로 약사국시 풀어보니...응시생 평균 정답률 상회
- 정흥준
- 2024-11-18 11:43:07
-
가
- 가
- 가
- 가
- 가
- 가
-




- 유상준 약사, 국시 활용한 언어모델 성능평가 연구
- GPT 3.5와 4.0 정답률 차이 커...약사법규서 유일하게 과락
- PR
- 전국 지역별 의원·약국 매출&상권&입지를 무료로 검색하세요!!
- 데일리팜맵 바로가기
[데일리팜=정흥준 기자] 챗GPT 두 가지 버전으로 약사국가고시 문제를 풀어보니, 버전에 따라 응시생 평균 정답률을 상회하는 흥미로운 연구 결과가 나왔다.
약학·약료 분야에서 언어모델 LLM(Large Language Model)의 성능 차이가 극명하게 나타난 것이다. 앞으로도 약료 분야 LLM의 성능을 보완하는 기준점이 될 수 있을 것으로 보고 있다.
유상준 약사(디어라운드 CTO)는 최근 약국학회에 ‘약사국가시험 문제를 활용한 언어모델 (LLM)의 성능평가를 주제로 연구논문을 발표했다.
미국과 일본 등 해외에서는 유사한 선행 연구들이 있지만 한국에서는 생소한 연구다. 약사자격을 검증하는 시험을 챗GPT 3.5와 4.0을 이용해 풀도록 하고 성능을 비교 분석했다.
시험 문제는 올해 치러진 제75회 약사국가시험 중 비공개 문제를 제외한 모든 문항을 가지고 진행됐다.
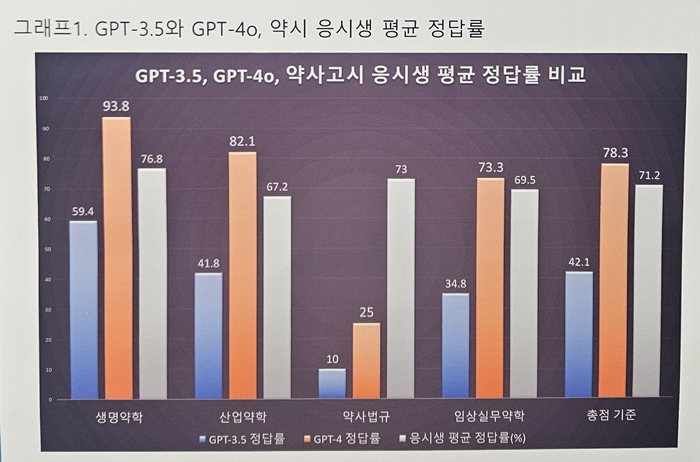
전문 용어와 임상적 지식이 필요한 복잡한 임상 문제를 풀어야 하는 ’임상실무약학2‘에서 특히 성능차이가 드러났다.
GPT 4.0은 약사법규를 제외한 모든 과목에서 실제 응시생 평균 정답률을 상회했다. GPT 3.5는 모든 과목에서 응시생 정답률을 하회했다.
약사법 특성상 어려운 용어, 달라지는 법 개정 등을 제대로 반영하지 못하는 것으로 분석했다. 유 약사는 이번 연구로 약료 LLM의 성능을 확인하는 기준을 마련하고, 약사법규 분야에서 성능 개선이 필요하다는 점을 파악했다.
유 약사는 “외국에는 국가고시 문제를 가지고 이뤄지는 언어모델 연구들이 많은 반면 국내에서는 이뤄지지 않아 연구를 진행해봤다”면서 “일단 두 가지 모델이 성능에 유의미한 차이점을 보였다는 점이 흥미롭다. 좋은 성능을 보여준 모델의 신뢰도를 확인할 수 있었다”고 설명했다.
이어 유 약사는 “새로운 모델을 만들 때 기능적 신뢰도를 평가하는 기준으로도 활용할 수 있다. GPT가 응시생 정답률을 상회한다고 해서 인력을 대체할 수 있다는 뜻은 아니다. 약사가 언어모델을 평가하며 관리해야 하는 것이고, 활용 후 판단에 대한 책임 또한 약사에게 있다”고 강조했다.
관련기사
-
약사회, AI 주제 온라인 컨퍼런스에 약사 1200명 참여
2024-10-22 11:50
-
AI·챗GPT, 약사 대체?..."셀러가 아닌 카운슬러가 돼라"
2024-09-29 16:37
-
"AI 신약, 왜 챗GPT만큼 성과 못 내나"…전문가 답변은
2024-09-26 12:00
- 익명 댓글
- 실명 댓글
- 댓글 0
- 최신순
- 찬성순
- 반대순
-
 개발팀 PV/MA/제제연구 부문별 경력채용
개발팀 PV/MA/제제연구 부문별 경력채용 -
 한국의약품안전관리원 개방형 직위 (의약품안전조사본부장) 채용 재공고
한국의약품안전관리원 개방형 직위 (의약품안전조사본부장) 채용 재공고 -
 [중앙보훈병원] 약제실 약사 채용
[중앙보훈병원] 약제실 약사 채용 -
 울진군의료원 약사 채용 공고
울진군의료원 약사 채용 공고 -
 Specialist, Hematology and Oncology Marketing
Specialist, Hematology and Oncology Marketing -
 CTD담당/국내 RA 경력 채용
CTD담당/국내 RA 경력 채용 -
Senior Manager, Government Affairs & External Liaison
-
 [서울 30분] 약제센터 야간 약사모집
[서울 30분] 약제센터 야간 약사모집 -
 [일산백병원] 약제부 계약직 야간약사 (신입/경력) 모집 공고
[일산백병원] 약제부 계약직 야간약사 (신입/경력) 모집 공고 -
 서울대학교병원 임상시험센터 약국 연구원 약사 채용 공고
서울대학교병원 임상시험센터 약국 연구원 약사 채용 공고 -
 삼성서울병원 (주말전담) 약제부 계약직 약사 채용
삼성서울병원 (주말전담) 약제부 계약직 약사 채용 -
 에스티팜 품질/제조관리 약사 상시모집
에스티팜 품질/제조관리 약사 상시모집 -
 5/29(금) 하루 근무하실 약사님 연락부탁드립니다~
5/29(금) 하루 근무하실 약사님 연락부탁드립니다~ -
 RPT 약리/의약화학 연구원 모집
RPT 약리/의약화학 연구원 모집 -
 고려대학교의료원(안암병원) 신규 교직원(정규직) 모집(약제팀 약사)
고려대학교의료원(안암병원) 신규 교직원(정규직) 모집(약제팀 약사) -
 경남 함안공장 제조관리약사 책임자 채용
경남 함안공장 제조관리약사 책임자 채용 -
 원주 공장 관리약사 채용 경력무관(신입우대)
원주 공장 관리약사 채용 경력무관(신입우대) -
 [강동성심병원] 약사 채용공고(ASP전담 / 정규직 약사)
[강동성심병원] 약사 채용공고(ASP전담 / 정규직 약사) -
 CV 마케팅부 PM 경력사원 채용
CV 마케팅부 PM 경력사원 채용 -
 한국에자이 QA Associate 채용
한국에자이 QA Associate 채용 -
 [바이엘코리아] MSL I Radiology (약 18개월 육아휴직 대체 계약직, 공고 연장)
[바이엘코리아] MSL I Radiology (약 18개월 육아휴직 대체 계약직, 공고 연장) -
 약제본부 야간약사 채용 안내
약제본부 야간약사 채용 안내 -
 해외사업본부 PIS팀 약사 채용
해외사업본부 PIS팀 약사 채용 -
 전북특별자치도마음사랑병원 주간약사 채용공고
전북특별자치도마음사랑병원 주간약사 채용공고 -
 [구미차병원] 약제팀 야간약사 모집
[구미차병원] 약제팀 야간약사 모집 -
대외협력실 PR(Public Relations) 경력사원(계약직) 채용
-
 로뎀요양병원 약사님 모십니다.
로뎀요양병원 약사님 모십니다. -
CV부 MR 정규직 경력사원 채용(창원 지역)
-
 [부산보훈병원] '26년 정규직 약사 공개채용
[부산보훈병원] '26년 정규직 약사 공개채용 -
 계명대학교 동산의료원 2026학년도 임시직(야간약사) 계약직원 상시 공개채용 공고
계명대학교 동산의료원 2026학년도 임시직(야간약사) 계약직원 상시 공개채용 공고 -
 [대자인병원] 약제팀 약사 / ASP팀 감염전문약사 모집
[대자인병원] 약제팀 약사 / ASP팀 감염전문약사 모집 -
 '정규직 약사' '야간약사' '주말약사' 채용
'정규직 약사' '야간약사' '주말약사' 채용 -
 정규직 2026년 신입 약사 채용
정규직 2026년 신입 약사 채용 -
 약제팀 (협약직) 야간약사 모집
약제팀 (협약직) 야간약사 모집 -
 의정부/노원을지대학교병원 약사 채용
의정부/노원을지대학교병원 약사 채용

약국e몰
![[노보노디스크] 위고비](https://cdn.platpharm.co.kr/static/dailypharm/Wigobi.png)
![[옵투스] 오에수 시리즈](https://cdn.platpharm.co.kr/2026/02/2602130209000031633.webp)
![[종근당] 브레이닝캡슐](https://cdn.platpharm.co.kr/2025/06/2506040708450012544.png)
![[신신제약] 아렉스마일드](https://cdn.platpharm.co.kr/2023/11/2311300927130000133.jpg)
![[유한양행] 안티푸라민 파스 시리즈](https://cdn.platpharm.co.kr/2024/05/2405280631070000069.png)
![[신신제약] 모스키토 밀크](https://cdn.platpharm.co.kr/2025/10/2510150733400004067.webp)
![[일양약품] 도담도담 시리즈](https://cdn.platpharm.co.kr/2024/02/2402020935180000240.jpg)
![[삼진제약] 게보핏 시리즈](https://cdn.platpharm.co.kr/2024/07/2407100728250000386.png)
![[유한양행] 마그비 시리즈](https://cdn.platpharm.co.kr/2024/03/2403261023280000193.jpg)
![[일양약품] 프로엑스피](https://cdn.platpharm.co.kr/2026/01/2601221008450010125.webp)
![[리쥬올] PDLLA 퍼밍 크림 30ml](https://cdn.platpharm.co.kr/2026/04/2604070229110000386.webp)
![[경방신약] 방콜브이산](https://cdn.platpharm.co.kr/2025/12/2512310630020002495.webp)
![[켄뷰] 다양한 통증에, 타이레놀정 500mg 10정](https://i.baropharm.com/products/6c6ea4f4-7ab2-44f2-a165-f062d80f525b.png)
![[경동제약] 인태반 자양강장제, 파워콤프](https://i.baropharm.com/partner/products/0a2cbb4c-96c5-40a5-aec2-8beeae11682c.png)
![[한독] 붙이는 통증 전문가, 케토톱 액티브 플라스타(쿨) 40매](https://i.baropharm.com/products/202503/1741829602305.png)
![[쥬베룩] 진짜 쥬베룩을 담은 약국전용 PDLLA 크림](https://i.baropharm.com/products/202604/1775343960671.png?label=바뷰페로고)
![[리쥬올] 닥터 리쥬올 어드밴스드 PDRN 리쥬비네이팅 크림 30ml](https://i.baropharm.com/partner/products/a201d2b4-f21e-4b13-957c-846d286b3d21.jpg?label=바뷰페로고)
![[켄뷰] 오리지널 폼타입, 로게인5%폼에어로졸60g](https://i.baropharm.com/products/dc84d96e-d0b4-46bc-bcc8-d62016406fe4.png)
![[아워팜] 우리아이 맞춤설계, 바로타민 kids 엘더베리맛](https://i.baropharm.com/partner/products/3f39593e-6318-4dd9-a778-c008c868b5c8.png)
![[아워팜] CJ웰케어, 바이오코어 1000억 유산균](https://i.baropharm.com/products/202604/1776750298620.png)
![[휴온스 ] 비듬을 한번에, 니조랄 2%액](https://i.baropharm.com/products/478a284d-4361-4b4a-8a00-8bab80f34319.png?label=PLAN_01)
![[레비온] PDRN+EGF, 레비온RX PDRN EGF 크림](https://i.baropharm.com/products/202512/1765949426601.png)
![[알엑스미] 알엑스미 리쥬영 울트라 PDRN 10000 딥리페어 크림](https://i.baropharm.com/partner/products/70c72dd0-cfd3-4d80-87e4-dc4f8de6658b.png?label=바뷰페로고)
![[CHD제약] 50년 전통의 천혜당 식염포도당](https://i.baropharm.com/products/202604/1775095858899.png)
오늘의 TOP 10
- 1"사실상 강매" 약국 울리는 제약사 품절 마케팅
- 2기넥신 처방액 3년새 49% 상승…이유있는 늦깎이 전성기
- 3피타바스타틴1mg+에제티미브 복합제 시장에 대원 가세
- 4발기부전약 '타다라필' 함유 캔디 수입·판매 일당 적발
- 5복약지도 부실 논란 의식?...창고형 약국의 건강 강연
- 6마약류 수거 전국 약국 100곳으로 확대…서울시도 참여
- 7HK이노엔 '크레메진속붕정' 잔류용매 우려 자진회수
- 8남자 청소년 HPV 예방 확대…"접종 사각지대 해소 시작"
- 9한올 '아이메로프루바트' 난치성 류마티스관절염 효능 확인
- 10복산-스즈켄 동행 10년…"한일 제약·도매 상생 플랫폼 도약”




