
















챗GPT로 약사국시 풀어보니...응시생 평균 정답률 상회
- 정흥준
- 2024-11-18 11:43:07
-
가
- 가
- 가
- 가
- 가
- 가
-




- 유상준 약사, 국시 활용한 언어모델 성능평가 연구
- GPT 3.5와 4.0 정답률 차이 커...약사법규서 유일하게 과락
- PR
- 전국 지역별 의원·약국 매출&상권&입지를 무료로 검색하세요!!
- 데일리팜맵 바로가기
[데일리팜=정흥준 기자] 챗GPT 두 가지 버전으로 약사국가고시 문제를 풀어보니, 버전에 따라 응시생 평균 정답률을 상회하는 흥미로운 연구 결과가 나왔다.
약학·약료 분야에서 언어모델 LLM(Large Language Model)의 성능 차이가 극명하게 나타난 것이다. 앞으로도 약료 분야 LLM의 성능을 보완하는 기준점이 될 수 있을 것으로 보고 있다.
유상준 약사(디어라운드 CTO)는 최근 약국학회에 ‘약사국가시험 문제를 활용한 언어모델 (LLM)의 성능평가를 주제로 연구논문을 발표했다.
미국과 일본 등 해외에서는 유사한 선행 연구들이 있지만 한국에서는 생소한 연구다. 약사자격을 검증하는 시험을 챗GPT 3.5와 4.0을 이용해 풀도록 하고 성능을 비교 분석했다.
시험 문제는 올해 치러진 제75회 약사국가시험 중 비공개 문제를 제외한 모든 문항을 가지고 진행됐다.
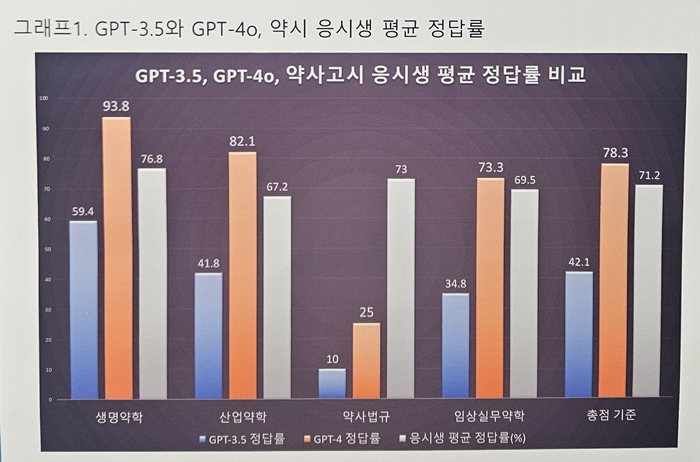
전문 용어와 임상적 지식이 필요한 복잡한 임상 문제를 풀어야 하는 ’임상실무약학2‘에서 특히 성능차이가 드러났다.
GPT 4.0은 약사법규를 제외한 모든 과목에서 실제 응시생 평균 정답률을 상회했다. GPT 3.5는 모든 과목에서 응시생 정답률을 하회했다.
약사법 특성상 어려운 용어, 달라지는 법 개정 등을 제대로 반영하지 못하는 것으로 분석했다. 유 약사는 이번 연구로 약료 LLM의 성능을 확인하는 기준을 마련하고, 약사법규 분야에서 성능 개선이 필요하다는 점을 파악했다.
유 약사는 “외국에는 국가고시 문제를 가지고 이뤄지는 언어모델 연구들이 많은 반면 국내에서는 이뤄지지 않아 연구를 진행해봤다”면서 “일단 두 가지 모델이 성능에 유의미한 차이점을 보였다는 점이 흥미롭다. 좋은 성능을 보여준 모델의 신뢰도를 확인할 수 있었다”고 설명했다.
이어 유 약사는 “새로운 모델을 만들 때 기능적 신뢰도를 평가하는 기준으로도 활용할 수 있다. GPT가 응시생 정답률을 상회한다고 해서 인력을 대체할 수 있다는 뜻은 아니다. 약사가 언어모델을 평가하며 관리해야 하는 것이고, 활용 후 판단에 대한 책임 또한 약사에게 있다”고 강조했다.
관련기사
-
약사회, AI 주제 온라인 컨퍼런스에 약사 1200명 참여
2024-10-22 11:50
-
AI·챗GPT, 약사 대체?..."셀러가 아닌 카운슬러가 돼라"
2024-09-29 16:37
-
"AI 신약, 왜 챗GPT만큼 성과 못 내나"…전문가 답변은
2024-09-26 12:00
- 익명 댓글
- 실명 댓글
- 댓글 0
- 최신순
- 찬성순
- 반대순
-
 동아대학교병원 약제부 약사 <정규직> 모집
동아대학교병원 약제부 약사 <정규직> 모집 -
 [서울 30분] 한림병원 약제센터 야간 약사모집
[서울 30분] 한림병원 약제센터 야간 약사모집 -
 일산차병원 약제팀 정규(주간)약사 채용
일산차병원 약제팀 정규(주간)약사 채용 -
 마케팅 실무 총괄 채용(경력 10년)
마케팅 실무 총괄 채용(경력 10년) -
 명인제약 【상반기】 경력사원 모집
명인제약 【상반기】 경력사원 모집 -
 기간제 약사를 모집합니다.
기간제 약사를 모집합니다. -
 약사 모집
약사 모집 -
 계명대학교 동산의료원 2026학년도 임시직(야간약사) 계약직원 상시 공개채용 공고
계명대학교 동산의료원 2026학년도 임시직(야간약사) 계약직원 상시 공개채용 공고 -
 임상PM/제제개선/건기식개발담당 채용
임상PM/제제개선/건기식개발담당 채용 -
 경상북도 김천의료원 약사 채용
경상북도 김천의료원 약사 채용 -
 의정부/노원을지대학교병원 약사 채용
의정부/노원을지대학교병원 약사 채용 -
 [일산백병원] 약제부 계약직 야간/주말당직약사 (신입/경력) 모집 공고
[일산백병원] 약제부 계약직 야간/주말당직약사 (신입/경력) 모집 공고 -
 해외사업본부 PIS팀 약사 채용(경력무관)
해외사업본부 PIS팀 약사 채용(경력무관) -
 오산한국병원 계약직 약사 구인(육아휴직 대체구인)
오산한국병원 계약직 약사 구인(육아휴직 대체구인) -
 삼성서울병원 (주말전담) 약제부 계약직 약사 채용
삼성서울병원 (주말전담) 약제부 계약직 약사 채용 -
 기간제 약사님을 모십니다.
기간제 약사님을 모십니다. -
 (경력무관) 품질관리약사 채용
(경력무관) 품질관리약사 채용 -
 [광주보훈병원] 정규직 약무직(약사) 공개채용
[광주보훈병원] 정규직 약무직(약사) 공개채용 -
 개발팀 PV/MA/제제연구 부문별 경력채용
개발팀 PV/MA/제제연구 부문별 경력채용 -
 당진공장 품질관리약사 채용(신입우대)
당진공장 품질관리약사 채용(신입우대) -
 [SK바이오팜] CNS Research Center 연구원 경력 모집
[SK바이오팜] CNS Research Center 연구원 경력 모집 -
 세종 공장 품질관리약사 (3년↑)
세종 공장 품질관리약사 (3년↑) -
 가천대길병원 약제부 야간약사(계약직) 채용
가천대길병원 약제부 야간약사(계약직) 채용 -
 [강동성심병원] 약사 채용공고(ASP전담 / 주말 약사)
[강동성심병원] 약사 채용공고(ASP전담 / 주말 약사) -
 평택공장 제조관리약사 채용(경력무관)
평택공장 제조관리약사 채용(경력무관) -
 서울대학교병원 임상시험센터 약국 연구원 약사 채용 공고
서울대학교병원 임상시험센터 약국 연구원 약사 채용 공고 -
 부산광역시의료원 직원모집 공고(약사)
부산광역시의료원 직원모집 공고(약사)

약국e몰
![[유한양행] 안티푸라민 파스 시리즈](https://cdn.platpharm.co.kr/2024/05/2405280631070000069.png)
![[신신제약] 아렉스마일드](https://cdn.platpharm.co.kr/2023/11/2311300927130000133.jpg)
![[일양약품] 프로엑스피](https://cdn.platpharm.co.kr/2026/01/2601221008450010125.webp)
![[옵투스] 오에수 시리즈](https://cdn.platpharm.co.kr/2026/02/2602130209000031633.webp)
![[신신제약] 모스키토 밀크](https://cdn.platpharm.co.kr/2025/10/2510150733400004067.webp)
![[종근당] 브레이닝캡슐](https://cdn.platpharm.co.kr/2025/06/2506040708450012544.png)
![[리쥬올] PDLLA 퍼밍 크림 30ml](https://cdn.platpharm.co.kr/2026/04/2604070229110000386.webp)
![[경방신약] 방콜브이산](https://cdn.platpharm.co.kr/2025/12/2512310630020002495.webp)
![[유한양행] 마그비 시리즈](https://cdn.platpharm.co.kr/2024/03/2403261023280000193.jpg)
![[삼진제약] 게보핏 시리즈](https://cdn.platpharm.co.kr/2024/07/2407100728250000386.png)
![[일양약품] 도담도담 시리즈](https://cdn.platpharm.co.kr/2024/02/2402020935180000240.jpg)
![[노보노디스크] 위고비](https://cdn.platpharm.co.kr/static/dailypharm/Wigobi.png)
![[아워팜] CJ웰케어, 바이오코어 1000억 유산균](https://i.baropharm.com/products/202604/1776750298620.png)
![[켄뷰] 다양한 통증에, 타이레놀정 500mg 10정](https://i.baropharm.com/products/6c6ea4f4-7ab2-44f2-a165-f062d80f525b.png)
![[경동제약] 인태반 자양강장제, 파워콤프](https://i.baropharm.com/partner/products/0a2cbb4c-96c5-40a5-aec2-8beeae11682c.png)
![[휴온스 ] 비듬을 한번에, 니조랄 2%액](https://i.baropharm.com/products/478a284d-4361-4b4a-8a00-8bab80f34319.png?label=PLAN_01)
![[리쥬올] 닥터 리쥬올 어드밴스드 PDRN 리쥬비네이팅 크림 30ml](https://i.baropharm.com/partner/products/a201d2b4-f21e-4b13-957c-846d286b3d21.jpg?label=바뷰페로고)
![[CHD제약] 50년 전통의 천혜당 식염포도당](https://i.baropharm.com/products/202604/1775095858899.png)
![[한독] 붙이는 통증 전문가, 케토톱 액티브 플라스타(쿨) 40매](https://i.baropharm.com/products/202503/1741829602305.png)
![[켄뷰] 오리지널 폼타입, 로게인5%폼에어로졸60g](https://i.baropharm.com/products/dc84d96e-d0b4-46bc-bcc8-d62016406fe4.png)
![[쥬베룩] 진짜 쥬베룩을 담은 약국전용 PDLLA 크림](https://i.baropharm.com/products/202604/1775343960671.png?label=바뷰페로고)
![[레비온] PDRN+EGF, 레비온RX PDRN EGF 크림](https://i.baropharm.com/products/202512/1765949426601.png)
![[알엑스미] 알엑스미 리쥬영 울트라 PDRN 10000 딥리페어 크림](https://i.baropharm.com/partner/products/70c72dd0-cfd3-4d80-87e4-dc4f8de6658b.png?label=바뷰페로고)
![[아워팜] 우리아이 맞춤설계, 바로타민 kids 엘더베리맛](https://i.baropharm.com/partner/products/3f39593e-6318-4dd9-a778-c008c868b5c8.png)
![[여성재구매1위] 오니스트 트리플 콜라겐 액상 프리미엄](https://cdn.imweb.me/upload/S2025060969b2a2d28fb0a/e47b9791e6f11.jpg)
![[소아과문전픽] 야미얼스 유기농 젤리 엄마들이 찾는 간식](https://cdn.imweb.me/upload/S2025060969b2a2d28fb0a/ac4a307e0a63e.png)
![[16차 완판 신화] 환자들이 먼저 알아보는 1위 콜라겐 마스크](https://cdn.imweb.me/upload/S2025060969b2a2d28fb0a/18cc54913f205.jpg)
![[복약대효자템] 코빵에어 페퍼민트 코막힘 답답할때 필수](https://cdn.imweb.me/upload/S2025060969b2a2d28fb0a/0c57b4a3f02b9.png)
![[초저가더마] 약국 화장품 매대 필수! 비타민 크림](https://cdn.imweb.me/upload/S2025060969b2a2d28fb0a/9dddfbfed16c2.jpg)
![[요즘대세/수면] 젤라토닌 식물성 멜라토닌 1mg 구미](https://cdn.imweb.me/upload/S2025060969b2a2d28fb0a/8fb2533d57de4.png)
![[마진2배/1+1] 편한가몰 매주 업데이트되는 1+1 특가관](https://gi.esmplus.com/pyunhanga/timesale.jpg)
![[약사님복지템] 풀리오 종아리 마사지기 피로회복 필수품](https://cdn.imweb.me/upload/S2025060969b2a2d28fb0a/024771c0a3d5f.png)
![[객단가수직상승] 파스찾는 환자가 같이 사가는 프리미엄 안마기](https://cdn.imweb.me/upload/S2025060969b2a2d28fb0a/8cb1830429122.jpg)
![[2030유입템] 럽티 호박차 티백 V라인 이너뷰티 핫템](https://cdn.imweb.me/upload/S2025060969b2a2d28fb0a/70d5f9c5baba8.jpg)
![[신규매출/펫] 라이프펫 강아지 유산균 동물약국 필수템](https://cdn.imweb.me/upload/S2025060969b2a2d28fb0a/94f80101539a8.jpg)
![[정제수0%] 물 한방울 없이 콜라겐 60% 꽉 채운 PDRN](https://cdn.imweb.me/upload/S2025060969b2a2d28fb0a/0a838fb804879.png)
오늘의 TOP 10
- 1외형보다 체력, 남는 장사 집중…달라진 중소형제약 생존법
- 2마운자로·위고비, 3개월 매출 4천억…상반된 고용량 점유율
- 3삼진제약, 독감백신 완판…백신 개발로 보폭 넓힌다
- 4[데스크 시선] 휴온스 합병, 주주 소통의 정석
- 5"스타틴 부작용 과도한 우려...복용 혜택이 더 크다"
- 6시퀴러스, 독감백신 첫 NIP 도전 고배…입찰경쟁서 밀려
- 7"약국 수가 3.7% 인상 이유는 낮은 행위료와 환자수 감소"
- 8"나는 매일 아침 피를 봅니다"…1형 당뇨와 28년 함께한 약사
- 9중증 천식치료제 '테즈파이어', 종합병원 처방권 진입
- 10'비정상·가짜진료 조사반' 가동…과잉처방·가짜진료 타깃




